Longer-term dependency learning using Transformers-XL on SQuAD 2.0
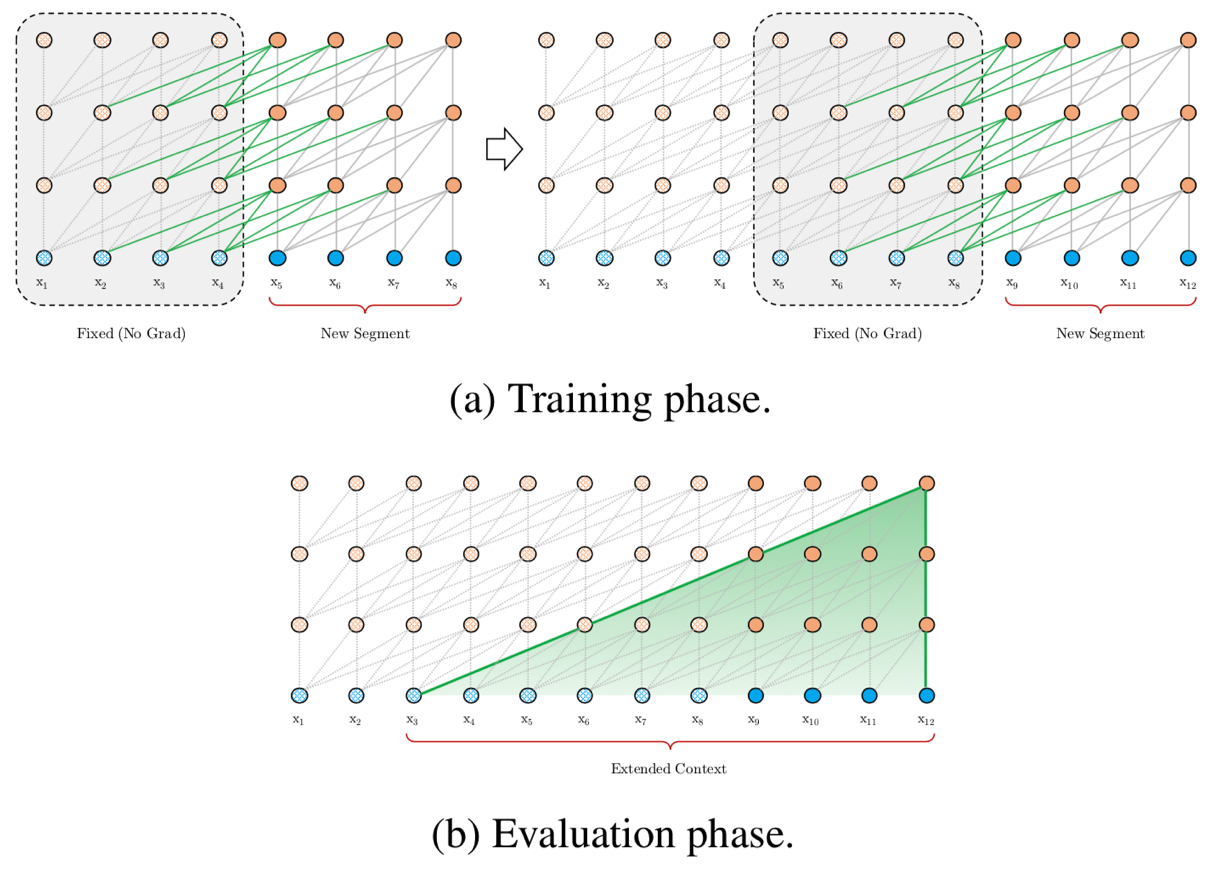
I propose an application of the Transformer-XL attention model to the SQuAD 2.0 dataset, by first implementing a similar architecture to that of QANet, replacing the RNNs of the BIDAF model with encoders, and then changing out the self-attention layer to that of Transformer-XL. In traditional transformers, there exists an upper dependency length limit equal to the length of this context. The Transformer-XL addresses these issues by caching the representations of previous segments to be reused as additional context to future segments, thus increasing the context size and allowing information to flow from one segment to the next. This longer-term dependency capture can be particularly useful when applying transformers to domains outside of natural language. Only a small improvement is shown with the Transformer-XL / QANet combined model compared to the baseline BIDAF, but increased performance is expected with additional parameter finetuning.