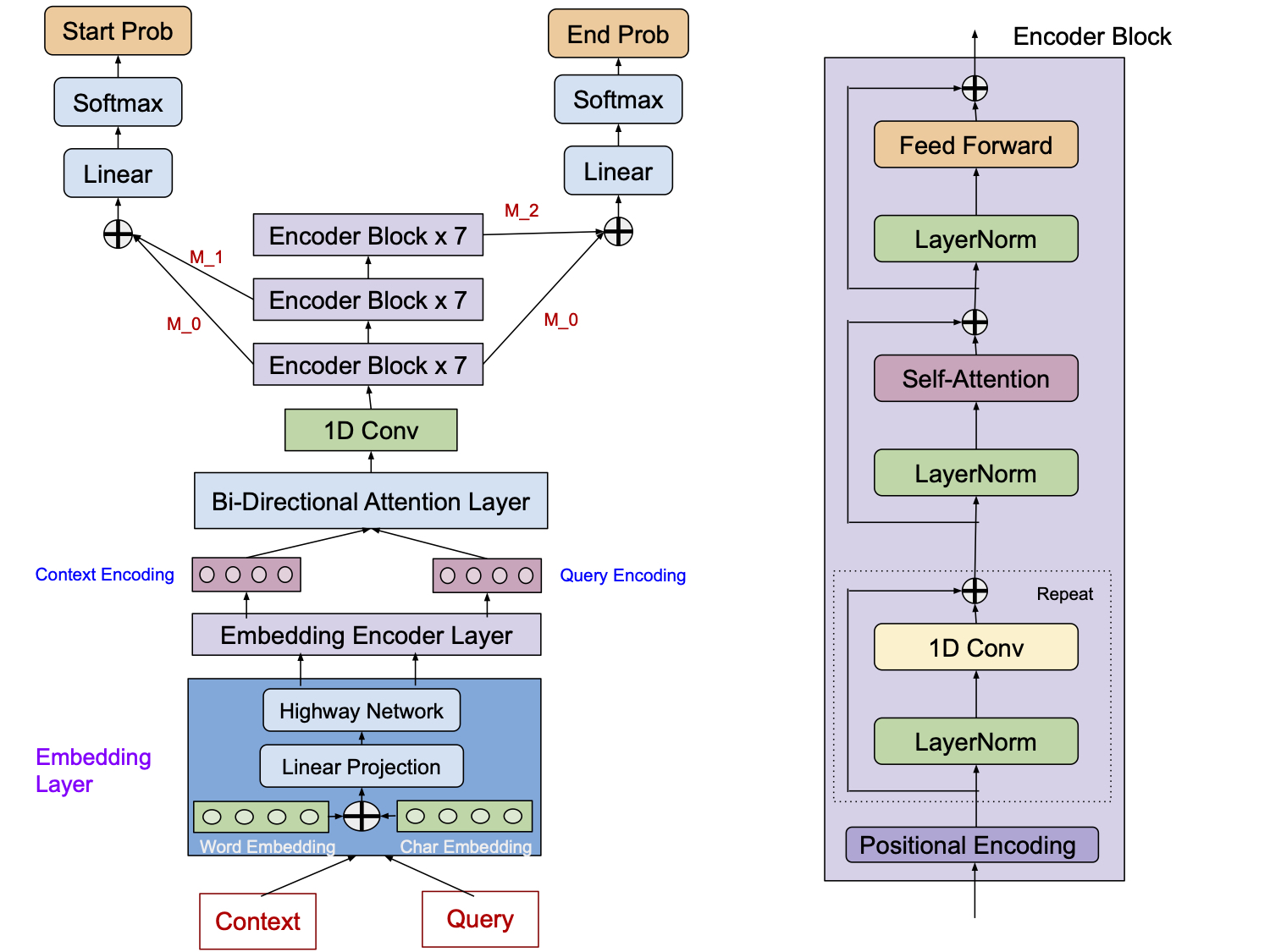
QANet model was one of the state-of-the-art models for SQuAD 1.1. Does its top-notch performance transfer to the more challenging SQuAD 2.0 dataset containing unanswerable questions? How does the model size affect performance? Is the bi-directional attention layer really necessary in a transformer-style architecture? These are the questions, I tried to answer in this project. Compared to the three baselines derived from the BiDAF model, QANet achieved substantially higher F1 and EM scores of 67.54 and 63.99 respectively. However, these scores are significantly lower than those of the current state-of-the-art models, mainly because the model couldn’t correctly handle unanswerable questions. Next, experiments with model size showed no performance degradation with smaller-sized QANet variants. In fact, these variants slightly outperformed the base QANet. Lastly, a new model built entirely using QANet’s building blocks (without an explicit bi-directional attention layer) outperformed all of the baseline models even without finetuning. Its performance is still below the base QANet model most likely because the model started overfitting roughly midway through training. I believe adding more regularization and further finetuning would bring its performance close to that of the base QANet model.