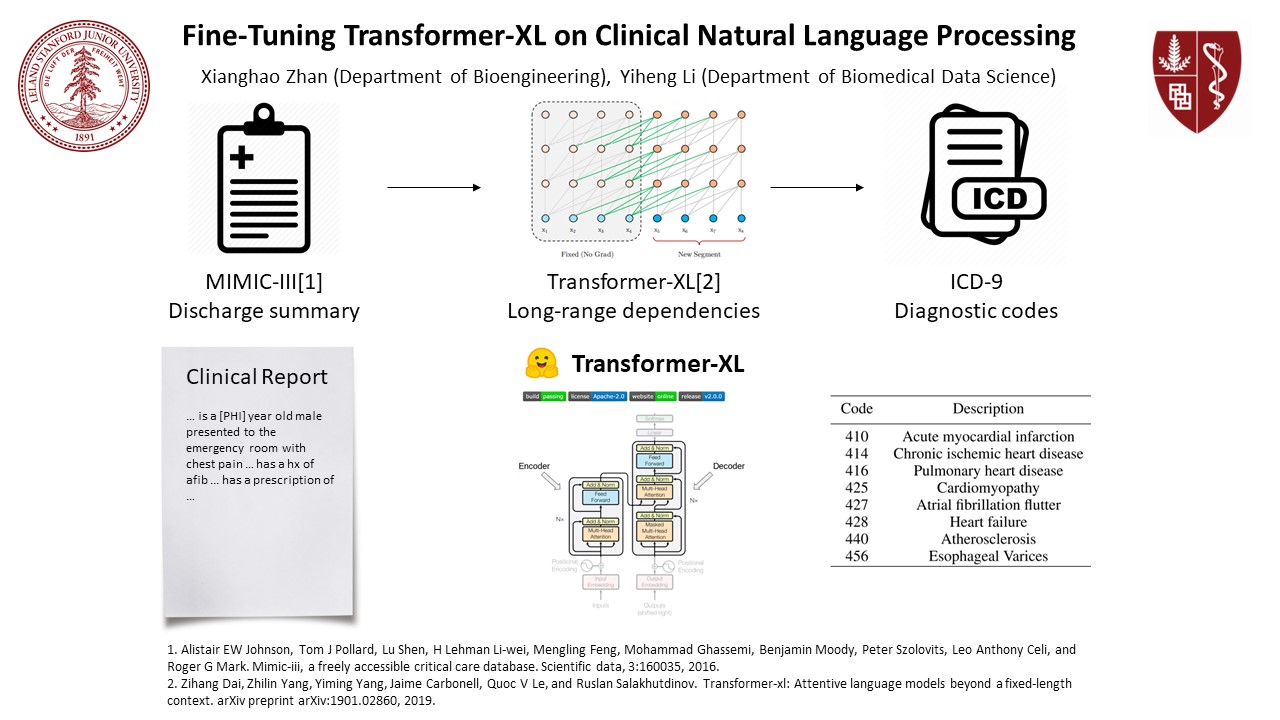
Fine-Tuning Transformer-XL on Clinical Natural Language Processing
Although many applications based-on mining clinical free text has been developed, the state-of-the-art transformer-based models have not been applied in clinical NLP. We aim to address the long-range dependencies in clinical free text caused by different sections with the latest Transformer-XL model by fine-tuning it on MIMIC-III clinical text. Having requested and cleaned the MIMIC-III clinical text based on self-developed rules, we prepared the data for training classifiers on diagnostic code prediction of 8 common cardiovascular diseases. We used huggingface API to fine-tune and evaluate Transformer-XL model on MIMIC-III dataset and compared the results with baseline methods including bag-of-words and TF-IDF. And the Transformer-XL outperformed the Bag-of-Words and TF-IDF on 3 of 6 tasks, on which we have already got the results. Furthermore, the Transformer-XL was only fine-tuned for 1 epoch, and therefore we believe there is a promising potential for a better fine-tuned Transformer-XL to better predict the diagnostic codes accurately. The better accuracy of diagnostic codes aids in the structuring of free-text clinical notes, which can be better and easier for downstream machine learning tasks, such as survival predictions and multi-modality data fusion, because the structured diagnostic codes can be fed into machine learning models than the unstructured data.